
Introduction
Les produits et les données cloud d’Atlassian sont hébergés sur Amazon Web Services (AWS), le principal fournisseur de services cloud du secteur. Les produits Atlassian fonctionnent sur une plateforme PaaS (Platform as a Service) qui est divisée en deux ensembles d’infrastructures principaux appelés « Micros » et « non Micros ».
Infrastructure cloud
Zones de disponibilité (ZD)
Pour Jira et Confluence, Atlassian utilise le mode de déploiement multi-ZD avec Amazon Relational Database Service (Amazon RDS). Cela garantit une réplication synchrone de secours dans une autre ZD de la même région pour assurer la redondance et la capacité de basculement. Le basculement de ZD est automatisé et prend généralement de 60 à 120 secondes, permettant ainsi aux opérations de la base de données impactée de reprendre aussi rapidement que possible sans intervention administrative. Opsgenie, Statuspage, Trello et Jira Align utilisent des stratégies de déploiement similaires, avec de légères variations dans la synchronisation des réplications et des basculements.
Emplacement des données
Les données Jira et Confluence sont hébergées, par défaut, dans la région la plus proche de celle où se trouve la majorité de vos utilisateurs lors de leur inscription. Toutefois, Atlassian propose la Data Residency si le client exige que ses données soient hébergées dans un endroit particulier. Actuellement, la Data Residency Atlassian couvre les États-Unis et dans l’Union Européenne ainsi qu’en Australie.
Sauvegardes de données
Atlassian utilise la fonctionnalité d’instantané Amazon RDS pour créer des sauvegardes quotidiennes automatisées de chaque instance RDS.
Les instantanés Amazon RDS sont conservés pendant 30 jours avec prise en charge de la reprise à un instant de référence et sont chiffrés avec l’algorithme AES-256. Les données de sauvegarde ne sont pas stockées hors site, mais sont répliquées dans plusieurs data centers au sein d’une région AWS spécifique. Des tests trimestriels des sauvegardes sont également réalisés.
Architecture de la plateforme cloud
Architecture de services distribuée
L’architecture basée sur AWS permet l’hébergement d’un ensemble de services produit et de plateforme utilisés dans l’ensemble des solutions Atlassian. Ces services englobent les fonctionnalités de la plateforme partagée et utilisée par plusieurs produits.
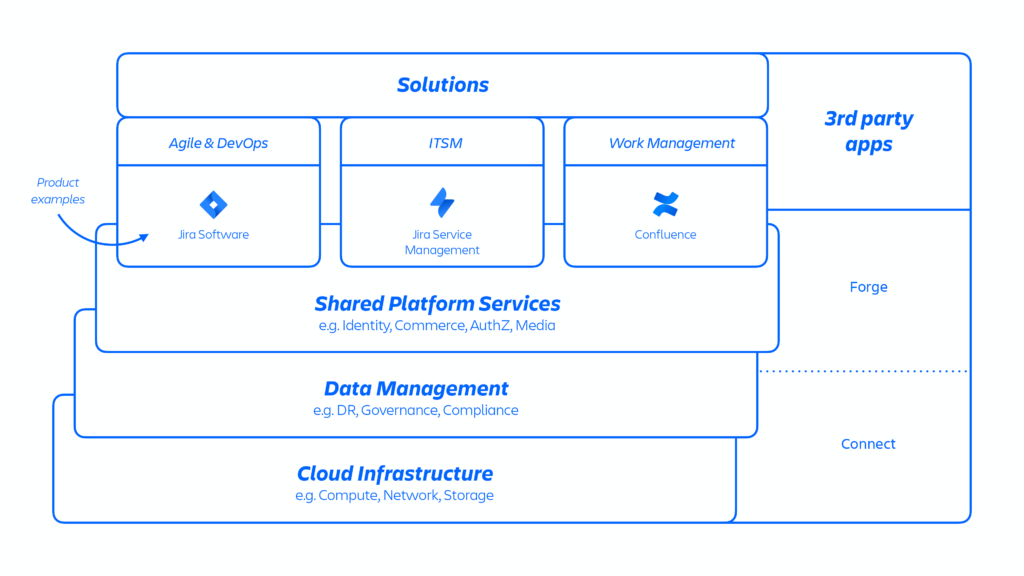
FIGURE 1 – Architecture de services distribuée
Atlassian offrent ces services via une Platform as a Service (PaaS) interne, nommée Micros, qui automatise le déploiement des services partagés, de l’infrastructure, des entrepôts de données, et de leurs fonctionnalités de gestion, incluant les exigences en matière de sécurité et de conformité (voir la Figure 1 ci-dessus). En général, un produit Atlassian se compose de plusieurs services conteneurisés déployés sur AWS à l’aide de Micros.
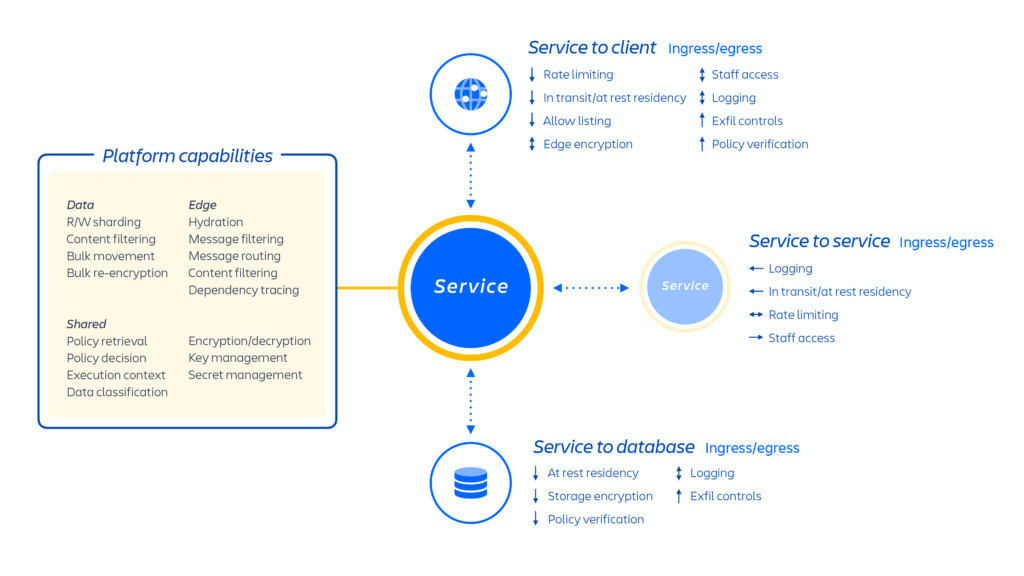
FIGURE 2 – Architecture de services
Architecture Multi-Tenant
L’architecture mise en place est une architecture de microservices multi-locataire avec une plateforme partagée qui prend en charge les produits Atlassian. Dans une architecture multi-locataire, un même service dessert plusieurs clients, y compris les bases de données et les instances de calcul nécessaires pour faire fonctionner les produits cloud. Chaque partition (essentiellement un conteneur, voir la Figure 3 ci-dessous) contient les données de plusieurs locataires, mais les données de chaque locataire sont isolées et inaccessibles aux autres locataires. Il est important de noter que Atlassian ne propose pas d’architecture dédiée à un seul locataire.
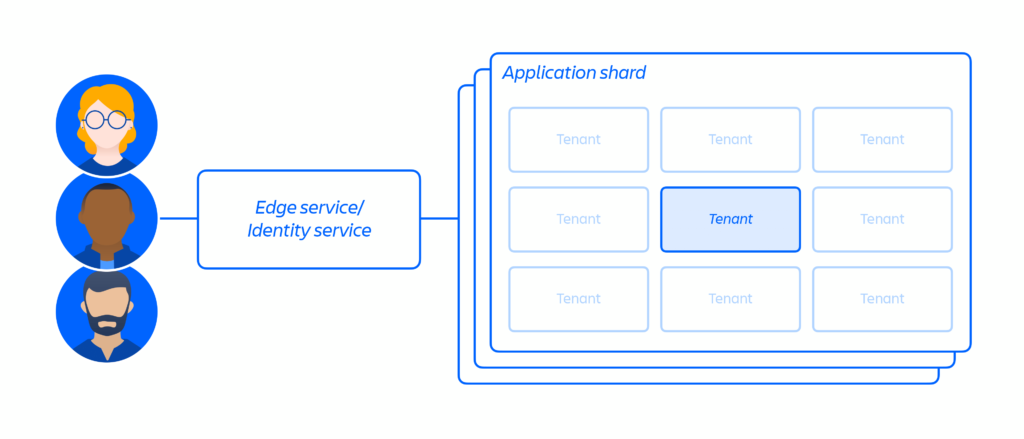
FIGURE 3 – Architecture Multi-Tenant
Les microservices sont conçus selon le principe du moindre privilège et sont configurés de manière à réduire la surface d’attaque pour tout exploit zero-day, ainsi que la probabilité de mouvements latéraux au sein de l’environnement cloud. Chaque microservice dispose de son propre stockage de données, uniquement accessible via le protocole d’authentification spécifique à ce service, garantissant ainsi qu’aucun autre service n’a accès en lecture ou en écriture à cette API.
Atlassian a opté pour l’isolation des microservices et des données, plutôt que sur la mise à disposition d’une infrastructure dédiée par locataire, car cela limiterait l’accès aux données pour de nombreux clients.
Provisionnement d’un locataire et cycle de vie
Lors de la mise en place d’un nouveau client, une série d’événements déclenche l’orchestration des services distribués et le provisionnement des entrepôts de données. Ces événements peuvent généralement être associés à l’une des sept phases du cycle de vie :
Les systèmes commerciaux sont immédiatement actualisés avec les dernières métadonnées et informations de contrôle d’accès pour ce client. Ensuite, un système d’orchestration du provisionnement aligne « l’état des ressources provisionnées » avec l’état de la licence au moyen d’une série d’événements liés au locataire et aux produits.
Événements associés au locataire
Ces événements impactent le locataire dans son ensemble et peuvent prendre deux formes :
- Création : un locataire est créé et utilisé pour de tout nouveaux sites
- Destruction : un locataire entier est supprimé
Événements associés aux produits
- Activation : après l’activation de produits sous licence ou d’apps tierces
- Désactivation : après la désactivation de certains produits ou de certaines apps
- Suspension : après la suspension d’un produit existant, désactivant ainsi l’accès à un site donné dont il est propriétaire
- Annulation de suspension : après l’annulation de la suspension d’un produit existant, permettant ainsi l’accès à un site dont il est propriétaire
- Mise à jour de licence : contient des informations concernant le nombre de postes de licence pour un produit donné ainsi que son état (actif/inactif)
Création du site client et activation de l’ensemble de produits approprié pour le client. Le concept d’un site est le conteneur de plusieurs produits concédés sous licence à un client spécifique. (p. ex. Confluence et Jira Software pour <nom-site>.atlassian.net).
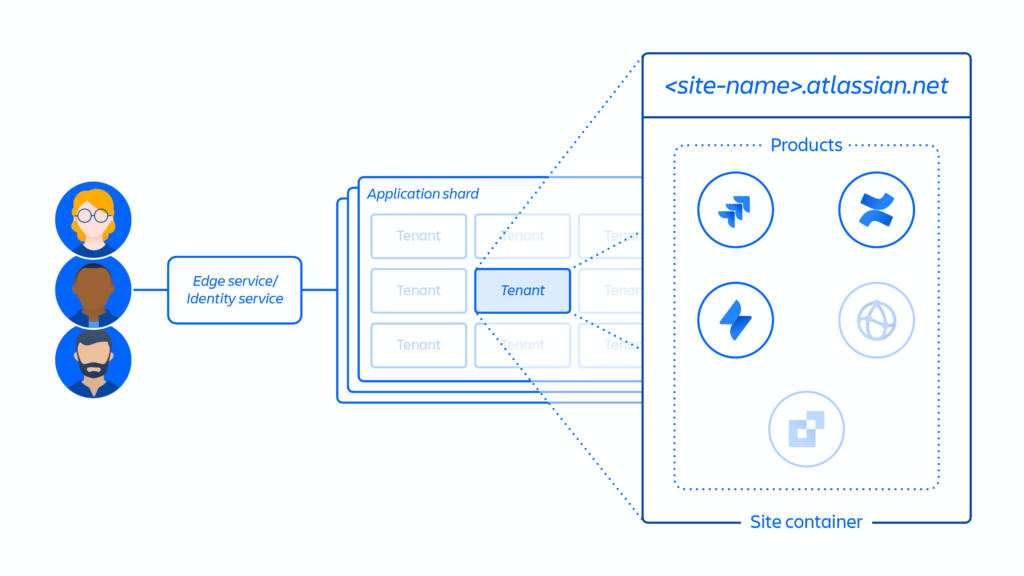
Figure 4 – Evénements associés aux produits
Lors du provisionnement d’un produit sur le site client dans la région spécifiée, le contenu du produit est principalement hébergé à proximité de l’emplacement où les utilisateurs y accèdent. Les données peuvent être déplacées entre les régions pour optimiser les performances. Certains produits offrent également la possibilité de choisir la résidence des données, permettant aux clients de décider si les données sont distribuées mondialement ou conservées dans des zones géographiques définies.
- Création et stockage de la configuration et des métadonnées de base du site client et des produits.
- Création et stockage des données d’identité du site et des produits, comme les utilisateurs, les groupes, les autorisations, et bien plus encore.
- Provisionnement de bases de données de produits sur un site, p. ex. gamme de produits Jira, Confluence, Compass ou Atlas.
- Provisionnement des apps sous licence des produits.
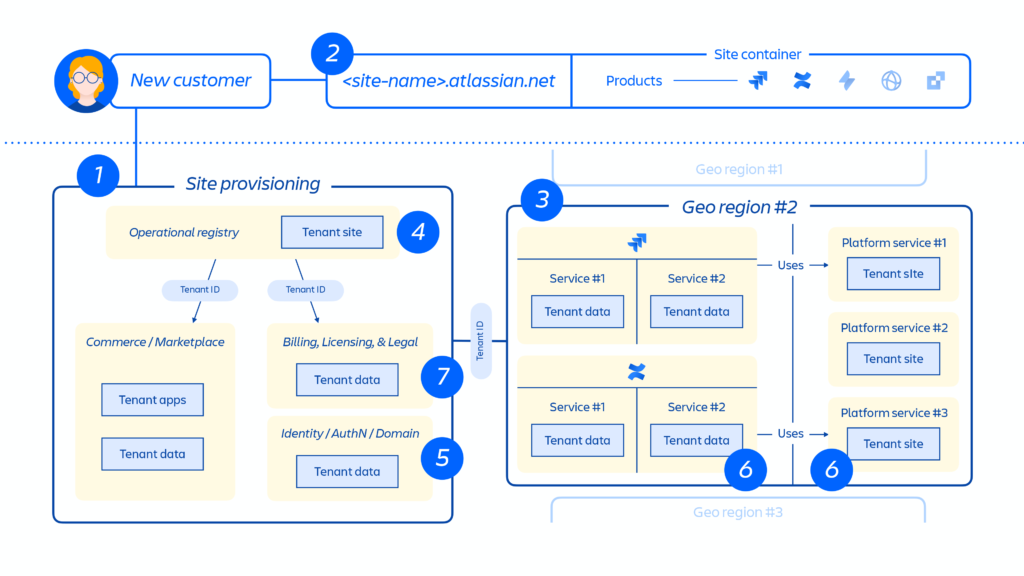
Figure 5 – Déploiement d’un site client au sein de l’infrastructure distribuée d’Atlassian
La représentation schématique dans la Figure 5 dépeint le déploiement d’un site client au sein de l’infrastructure distribuée d’Atlassian, englobant non seulement une seule base de données ou un unique entrepôt. Elle englobe divers emplacements physiques et virtuels qui abritent des métadonnées, des paramètres de configuration, des données propres au produit et à la plateforme, ainsi que d’autres informations associées au site.
Isolement des locataires
Bien que les clients d’Atlassian partagent une infrastructure commune lorsqu’ils utilisent les produits cloud, un isolement logique est mis en place afin que les actions d’un client ne puissent compromettre les données ou le service d’autres clients.
Pour Jira et Confluence Cloud, Atlassian utilise un concept appelé « Contexte de locataire » pour parvenir à cet isolement logique. Ce concept est intégré dans le code applicatif et est géré par un service dédié appelé (Tenant Context Service, TCS). Le TCS s’assure que :
- les données de chaque client sont logiquement isolées de celles des autres locataires au repos ;
- toutes les requêtes traitées par Jira ou Confluence offrent une vue propre à chaque locataire, évitant ainsi tout impact sur les autres locataires.
En résumé, le TCS conserve un contexte pour chaque locataire du client. Chaque contexte est associé à un identifiant unique stocké de manière centralisée par le TCS. Il contient diverses métadonnées relatives à ce locataire, telles que les bases de données associées, les licences, les fonctionnalités disponibles, et d’autres paramètres de configuration. Lorsqu’un client accède à Jira ou Confluence Cloud, le TCS utilise l’identifiant du locataire pour récupérer ces métadonnées, qui sont ensuite associées à toutes les opérations effectuées par le locataire dans l’application pendant sa session.
Limites Atlassian
Los données client bénéficient également d’une protection par le biais d’une « limite » : des barrières virtuelles érigées autour du logiciel. Lorsqu’une requête arrive, elle est dirigée vers la limite la plus proche. Après une série de vérifications, elle est soit autorisée, soit refusée.
Voici le processus :
- La requête atteint la limite Atlassian la plus proche de l’utilisateur. Cette limite vérifie la session et l’identité de l’utilisateur via votre système d’identité.
- La limite détermine où sont localisées les données de vos produits, en se basant sur les informations fournies par le TCS.
- La limite transfère la requête vers la région cible, où elle est traitée par un nœud de calcul.
- Le nœud utilise le système de configuration du locataire pour obtenir des détails, tels que l’emplacement de la licence et de la base de données. Il interagit ensuite avec d’autres magasins de données et services pour récupérer les informations nécessaires afin de répondre à la requête.
Contrôles de sécurité
Du fait que les produits cloud reposent sur une architecture multilocataire, il est possible d’incorporer des mesures de sécurité supplémentaires dans la logique de l’application qui est décorrélée. En comparaison, une application monolithique par locataire ne serait généralement pas en mesure d’ajouter des contrôles d’autorisation supplémentaires ou de gérer la limitation du débit, notamment en cas de volume élevé de requêtes ou d’exportations. De plus, l’impact d’une éventuelle faille de sécurité (« exploit zero-day ») est grandement réduit à mesure que la surface d’attaque des services diminue.
En complément, des mécanismes de contrôle préventifs supplémentaires ont été intégrés. Ils incluent :
- L’authentification et l’autorisation des services
- Le Service de Contexte de Locataire (TCS)
- La gestion des clés
- Le chiffrement des données
Authentification et autorisation de services
La plateforme Atlassian applique un modèle de moindre privilège en matière d’accès aux données. Cela signifie que chaque jeu de données est restreint au service spécifique responsable de son enregistrement, de son traitement ou de sa récupération. Par exemple, les services multimédias, qui assurent une expérience homogène de chargement et de téléchargement de fichiers sur tous les produits cloud, disposent d’un stockage exclusif auquel aucun autre service Atlassian n’a accès. Tout service nécessitant l’accès à ces contenus multimédias doit interagir avec l’API dédiée aux services multimédias. Ainsi, une authentification et une autorisation rigoureuses au niveau de la couche de service garantissent une séparation des tâches efficace et un accès aux données conforme au principe du moindre privilège.
Les jetons web JSON (JWT) sont utilisés pour garantir l’intégrité des signatures en dehors de l’application, afin que les systèmes d’identité et le contexte du locataire soient la source de référence. Ces jetons ne peuvent être utilisés que dans les limites de leurs autorisations. Lorsqu’un utilisateur sollicite un microservice ou une partition, les jetons sont transmis au système d’identité et validés en conséquence. Cette procédure assure que le jeton est à jour et authentifié avant tout partage des données appropriées. Ainsi, en cas de compromission d’un service, son accès est circonscrit grâce à cette méthode, associée aux exigences d’authentification et d’autorisation nécessaires pour atteindre ces microservices.
Les systèmes d’identité peuvent parfois faire l’objet de compromissions. Pour atténuer ce risque, deux mécanismes ont été mis en place . Tout d’abord, le TCS et les proxys d’identité sont hautement redondants. Un TCS supplémentaire est mis en place pour presque tous les microservices et des proxys supplémentaires qui émanent de l’autorité d’identité sont utilisés, de sorte que des milliers de ces services sont en cours d’exécution à tout moment. Si un comportement anormal est détecté dans l’un d’entre eux, Atlassian est en mesure d’intervenir rapidement et de remédier à la situation.
De plus, Atlassian met en œuvre divers programmes de sécurité pour identifier et contrer les menaces de sécurité.
Service de contexte de locataire (TCS)
Atlassian s’assure que les requêtes adressées à tous les microservices contiennent des métadonnées concernant le client (ou le locataire) sollicitant l’accès. C’est le service de contexte de locataire (TCS). Il est alimenté directement à partir des systèmes de provisionnement. Lorsqu’une demande est initiée, le contexte est extrait et intégré ans le code de service en cours d’exécution, qui est utilisé pour autoriser l’utilisateur. Tous les accès au service (et donc aux données) dans Jira et Confluence nécessitent ce contexte de locataire, sans quoi la demande sera rejetée.
L’authentification et l’autorisation des services sont mises en œuvre à travers le protocole d’authentification Atlassian Service Authentication Protocol (ASAP). Une liste blanche explicite détermine quels services peuvent communiquer, tandis que des informations d’autorisation précisent les commandes et les chemins disponibles. Cette approche limite tout potentiel de déplacement latéral en cas de compromission d’un service.
L’authentification et l’autorisation des services, ainsi que le flux de sortie, sont surveillées par un ensemble de proxys dédiés. Ainsi, les vulnérabilités du code de l’application n’ont aucun impact sur ces contrôles. Pour qu’une exécution de code arbitraire (RCE) ait lieu, il faudrait compromettre l’hôte sous-jacent et contourner les limites du conteneur Docker, et non simplement être en mesure de modifier la logique de l’application. Le système de détection d’intrusions au niveau de l’hôte signale les incohérences à cet égard.
Ces proxys restreignent le comportement de sortie en fonction des activités prévues pour chaque service. Les services qui n’ont pas besoin d’émettre des webhooks ou de communiquer avec d’autres microservices n’ont pas l’autorisation de le faire.
Cryptage de données
Les données clients stockées dans les produits cloud d’Atlassian sont sécurisées lors de leur transit sur les réseaux publics. Cela est réalisé en utilisant le protocole TLS (Transport Layer Security) 1.2+ avec PFS (Perfect Forward Secrecy), garantissant ainsi leur protection contre toute divulgation ou altération non autorisée. La mise en œuvre du TLS exige l’utilisation de cryptages robustes et de longues clés lorsque le navigateur les prend en charge.
Par ailleurs, les disques de données sur les serveurs hébergeant les données client et les pièces jointes dans Jira Software Cloud, Jira Service Management Cloud, Jira Work Management, Bitbucket Cloud, Confluence Cloud, Statuspage, Opsgenie et Trello bénéficient d’un chiffrement complet au repos. Cette méthode repose sur l’algorithme de chiffrement AES avec une clé de 256 bits, une norme de l’industrie.
En ce qui concerne les informations d’identification personnelle (PII) transmises via un réseau de transmission de données, elles sont soumises à des contrôles appropriés visant à garantir qu’elles atteignent la destination prévue. La politique interne d’Atlassian en matière de cryptographie et de chiffrement énonce les principes généraux qui guident la mise en œuvre de ces mécanismes pour réduire les risques liés au stockage et à la transmission des PII sur les réseaux. Le choix de l’algorithme de chiffrement pour les PII doit être en accord avec la classification de ces données, conformément aux principes de sécurité des données et de gestion du cycle de vie de l’information chez Atlassian.
Pour rester informé des fonctionnalités additionnelles relatives au chiffrement des données, veuillez consulter la feuille de route Atlassian Cloud.
Gestion des clés
Chez Atlassian, la gestion des clés est faite l’aide du service AWS Key Management Service (KMS) pour . KMS agit en tant qu’initiateur et gardien secret de ces clés, renforçant ainsi la confidentialité des données. Le processus de chiffrement, déchiffrement et gestion des clés est régulièrement soumis à une inspection et à une vérification en interne par AWS, conformément à ses procédures de validation existantes. Chaque clé est assignée à un propriétaire, qui a pour responsabilité de veiller à ce qu’un niveau de contrôle de sécurité adéquat soit appliqué.
De plus, Atlassian a opté pour la mise en place du chiffrement des enveloppes. La clé principale est détenue par AWS et demeure invisible par Atlassian. Toute requête de chiffrement ou de déchiffrement de clé nécessite les autorisations et rôles AWS appropriés. Lorsque Atlassian utilise le chiffrement des enveloppes pour créer ou générer des clés pour des clients spécifiques, différentes clés de données sont utilisées pour différents types d’informations, stockées dans leurs entrepôts de données. En parallèle, Atlassian a instauré un chiffrement de couche applicative interne qui assure des clés de données de secours dans d’autres régions AWS. Ces clés sont automatiquement renouvelées chaque année, et une même clé de données n’est pas utilisée pour plus de 100 000 éléments de données.
Dans un avenir proche, Atlassian compte mettre en place le chiffrement BYOK, offrant ainsi la possibilité de chiffrer les données de produits cloud avec des clés gérées par les clients dans AWS KMS. Grâce à ce système, les clients auront un contrôle total sur la gestion de leurs clés et pourront accorder ou révoquer l’accès à tout moment, tant pour leurs utilisateurs finaux que pour les systèmes Atlassian.
AWS KMS peut être intégré à AWS CloudTrail dans le compte AWS, fournissant ainsi des journaux de toutes les utilisations des clés. Cette solution permet le chiffrement des données à différents niveaux applicatifs, comme les bases de données, le stockage de fichiers, ainsi que les caches internes et la mise en file d’attente des événements. Tout au long de ce processus, l’expérience utilisateur ne sera en aucun cas impactée.